 Internet Society – San Francisco Bay Area Chapter
Internet Society – San Francisco Bay Area ChapterMischa Spiegelmock, Chair of the SF-Bay ISOC Chapter’s Working Group on IoT, Internet Technologies and Access, attended the recent Internet Engineering Task Force (IETF) 99 Meeting in Prague, Czech Republic. Find out about his experience as a first-timer in his comprehensive report below.

The Internet Engineering Task Force (IETF) is an organization dedicated to stewardship of an ever-expanding body of technical standards to facilitate interoperation of machines and software connected to the internet. Pretty much everything you can do on the internet, including the functioning of the internet itself, is governed by the IETF “Request For Comments” documents known as RFCs. Some standards defined in the RFCs include TCP/IP (internet), SMTP (email), IRC (chat), XMPP (jabber), emergency telephone call information, live video streaming and multitudes more.

The Internet Society facilitates much of the IETF’s work by providing administrative and organizational resources. There is no formal membership roster or special recognition given to governments or corporations. While most of the roughly 1,200 IETF attendees (except for your correspondent) were sent on trips with all expenses paid by their employer or through the IETF fellowshipprogram, there is a strong understanding that everyone there is representing themselves in technical matters. They are all expected to only state opinions they are personally willing to stand behind. The criteria for acceptance of moving IETF drafts forward are “rough consensus and running code,” though the “running code” part is less of a thing these days than it used to be. To get involved in the process all you have to do is join a working group (WG) mailing list. Anyone can attend of the tri-annual meetings, which are usually held in North America, Europe, and Asia.

Everything at the meetings including WG notes, audience questions, and meeting materials are recorded and made publicly available along with a live video stream with remote participation.
One of this year’s meetings was held in Prague, a frequent location for the Europe area. It was held at the Prague Hilton, and as part of the event contract the IETF replaced the hotel’s network with its own, setting up their BGP ASN and a multitude of wireless networks with 802.1X, IPv6-only and NAT64 experimental options, and a DHCP server handing out globally routable addresses with no firewall. As one should expect, the IETF doesn’t screw around when it comes to the meeting network.
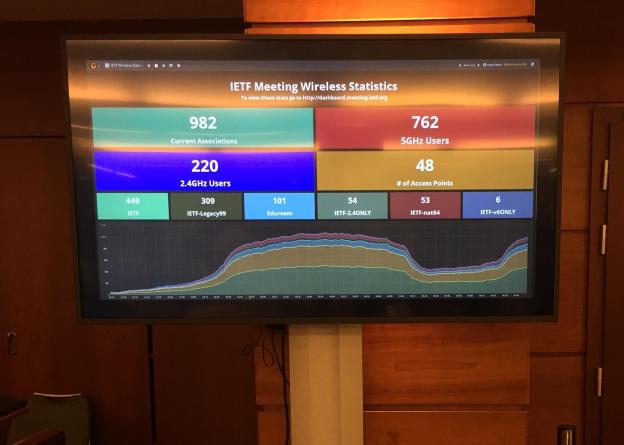
The work of the IETF is divided into subject “areas” which are made up of many working groups related to the area. The areas are the internet, operational issues and network management, routing, security, transport, applications and real-time, and general for more meta work.
Each working group in an area has a well-defined charter describing its purpose, and background materials to help frame the discussion. The work done by a WG almost all happens on its dedicated mailing list, with updates and discussion that is much easier to do face-to-face taking place at the meetings in person or via remote video conference.
In addition to the WGs, there are BoF sessions. A BoF (pronounced boff) is a “birds of a feather” group where people who are interested in a topic can come discuss ideas and gauge interest and see if there is IETF-related work to be done on the topic. If so, a working group may emerge from the BoF.
And finally there are research groups which are set up for long-term collaboration on research topics. They have a less focused charter and pursue and share research about a particular topic instead of working towards explicit RFC publication deliverables.

The RG’s mailing lists are great places to learn about new developments and work being done by academics and in-the-field engineers in subjects of interest. Just this morning I got an email on the GAIA list from the president of the Internet Society of Togo stating that they are experiencing internet shutdowns in the country today.
Attending the IETF meeting in person I was able to see the working groups, research groups and a BoF in action. Allow me to share my first impressions and experiences as a total clueless newcomer.
netvc
The Internet Video Codec working group is attempting to subjectively and objectively test and compare several candidate video codecs for use on the internet. netvc is a follow-on to the remarkably successful work the IETF codec WG did on audio codecs, in particular the royalty-free, high-quality and efficient Opus codec.
The topic of non-proprietary codecs is near and dear to my heart and more important than most people realize. Right now if you want to put a video on the web and have it work in all browsers you have but one option: the h.264 video codec, licensed by the MPEG Licensing Association patent cartel. This codec is covered by many patents and is not free in any sense of the word. Mozilla and Google have support for more open and less patent-encumbered video codecs (Ogg Theora, VP8) in their browsers, with Google going far far out of their way to purchase the VP8 codec and release all patent claims in the hope of having an unrestricted and open codec for everyone on the internet to use without having to pay royalties or fear of getting sued. This didn’t work out quite as planned for two reasons, one being that Google wouldn’t indemnify codec users (and couldn’t reasonably do so under extremely perilous and burdensome US patent laws), and the other reason being that Microsoft and Apple refused to include support for this codec in their browsers. Not that it would have been a great amount of effort, as the code is freely available with open source implementations. Having a video format that would only work in some browsers doesn’t really cut it for content publishers so everyone is forced to use h.264 instead. Also by some unrelated weird coincidence Microsoft and Apple happen to belong to the MPEG-LA and get a share of royalties from encoder licenses.
This is a rather long-winded way of saying the standardization of a (relatively speaking) patent-unencumbered free codec is actually quite crucial in keeping basic modern internet functionality out of the greedy hands of a small number of corporations. This is the kind of hard work and battle that must be constantly fought to keep the internet as free and open to everyone that organizations like the IETF and Internet Society are always engaged in.
As a point of comparison between VP8 and the result of the netvc video codec selection, users will still unfortunately be in the exact same position with regards to patient indemnification. The IETF cannot guarantee to defend all users from patent trolls. Despite Google’s promotion of VP8/VP9 as an open standard for internet video many people have treated them as proprietary codecs and desired a non-proprietary alternative.
The netvc working group is evaluating the codecs AV1, VP9 and Thor. Part of the work of the group has been to establish requirements for comparing the codecs on metrics such as high- and low-latency performance (offline vs live encoding), decoder complexity (to optimize CPU/power consumption and hardware acceleration), perceptual quality, error resilience, and Weissman Score (just kidding about that last one).

The general requirements for the internet video codec are that it should be suitable for video calls, broadcast media, conferencing, telepresence, teleoperation, screencasting, and video storage. They are basically aiming to equal or best h.265 (successor to h.264) as far as quality and complexity.
There are double-blind tests that anyone can participate in to subjectively judge video and frame encoding quality in a split view. They test one quantization parameter at a time in both high- and low-latency modes. The gentleman presenting on subjective testing claimed that Mozilla has a 4k projector in the break room they make the interns do tests on for cookies, though I wasn’t super sure if he was serious or not. Approximately 12 viewers are required for each test to be statistically significant. Some of the test corpora include Minecraft Twitch videos, “netflix crosswalk” and “netflix tunnelflag”.
The codecs being compared are works in progress; AV1 has gained about 20% compression over the past year most of that in the past three months, though with about a 1000% increase in complexity.
AV1 complexity is best vs Thor and VP9. Thor and VP9 have similar profiles for complexity/speed tradeoff for mixed content. Thor measured better than VP9 for video conferences but not quite as good AV1. They believe it’s possible to get Thor to perform roughly as well as AV1 but with a fraction of the tools and added complexity.
Error resiliency was discussed quite a bit. Since video is open streamed at someone and decoded in near-realtime, ability to gracefully recover from packet loss is an important consideration. This is a complex problem involving careful trade-offs because a packet does not represent a frame that can be easily dropped. Most of the time the packets contain backwards-looking prediction information that is computing estimated motion vectors from previous frames and against reference frames that the decoder may or may not have received or decoded successfully. There is a certain amount of redundant information that can be part of the packetized payload but this is a tradeoff between resiliency and amount of video information that can be packed into a certain bitrate. VP9 can reference frame dependencies implicitly or explicitly (with RTP picture ID mappings); there’s no way to know from an RTP header if a dependent frame is available without parsing actual RTP packets. AV1 explicitly signals and codes frame IDs in the codec payload, there is a proposal to move to motion predictions from the most recent reference frame.
As far as color information in AV1, a technique is being adopted from Daala (a Xiph codec converging with Thor) called CfL – Chrome from Luma. There is a correlation between luma (brightness) and chroma (color) that can be used to predict chroma coefficients directly. It was reported that doing this in the frequency domain sucked, and they are currently proposing to do this in the spatial domain instead.

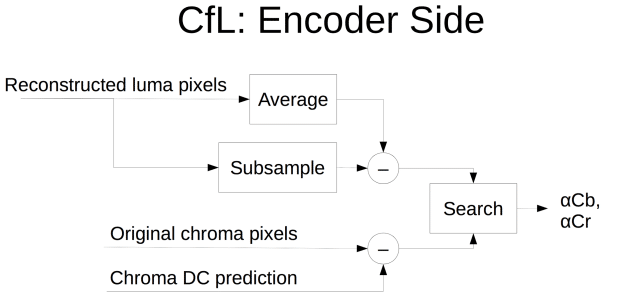
A notable thing about the netvc work has been the virtuous cycle of development it has brought. Simultaneous open development of AV1, Thor, VP9 and previous Daala with non-proprietary code and openly published test results has highlighted the ease and power of open-source collaborative development. Each project takes ideas from the others, improves upon them, and the improvements are fed back into the original project, in a cyclical fashion, with the work and results immediately available to everyone.
t2trg
Overheard at IETF99: “The ‘S’ in IoT stands for ‘Security’”.
The Thing To Thing Research Group (t2trg) highlighted security and interoperability issues with Internet of Things (IoT) devices.
Will IoT networks be friendly to each other? Some concerns exist about interference between vendors in terms of wireless spectrum usage, IP networks (imagine buying devices from different vendors that both want to be DHCP servers), multicast issues, sharing resources like an external IP address. “Every device vendor sees the network they operate on as a wide, big, empty road on which they are the only driver.”
Like UNIX, IoT is awesome because there are so many standards to choose from! There are different areas that different bodies focus on, but with a lot of overlap between schema.org, W3C, LwM2M, ISPO semantics and more.
Data interoperability is an issue too. Some data models have license terms that are opaque and hard to find out. I would suggest that any vendor trying to license their data models should just… not, but that is just my opinion.
A long-standing question has been service and resource discovery on the network. Imagine if you have a smoke detector from one vendor that wants to flash lights or play an alarm on speakers from other vendors. Multicast DNS is pretty accepted for this but it is fairly limited semantically. We really could use a standard for machine-readable resource enumeration and metadata. Part of the problem here is the difficulty of agreeing on a shared definition of what “metadata” is (just ask the NSA); it took the IETF four attempts to define metadata for security management. There are privacy concerns about announcing what resources a network has. You probably don’t want your pacemaker advertising control capabilities to anyone on the network. Some common infrastructure would be helpful, like a centralized IoT identifier registry. Right now most of the work the RG is doing is stored on repositories and wikis on GitHub.
There is an as-yet unsolved problem: if you buy an internet-connected device, how do you bootstrap security identifiers and credentials for your network and cloud services? How do you connect something to your wireless network that has no screen, or keyboard?

Research and a reference implementation were also presented about one solution for authorizing network access for IoT devices. The proposal, called EAP-NOOB(really), utilizes out-of-band (OOB) communication for network authorization and user account setup. Examples they gave were a smart TV that displays a QR code the user scans with their phone, or a camera taking a picture of a QR code presented on a phone. They suggested other OOB mechanisms such as an audio cable or NFC NDEF message.

perc
I attended the Privacy-Enhanced RTP conferencing WG.
The hard problem that the perc group is trying to solve is how to enable centralized Secure Real Time Protocol (SRTP) conferencing where the central device distributing the media is not required to be trusted with the keys to decrypt the participants’ media.
At the meeting they discussed obscure (to me) technical details regarding best ways to maintain and re-key Secure RTP communications for conferencing involving double-encrypting tunnel components and allowing RTP packet repair by media distributors.

There was an interesting presentation about RED – redundant encoding. This was in a similar vein to the netvc error resilience discussion, evaluating tradeoffs between less bandwidth efficiency and better handling of dropped packets. In the RED scheme, each RTP packet contains an alternative (low-quality) version of the previous frame for repair purposes, mostly for audio. The main idea being that if packet loss is detected in a poor quality conference, you could reduce some of the bandwidth used for video and instead allocate that to audio packet repair so that at least audio quality suffers less. Double-audio packets could even be handled by media distributors instead of the streaming source endpoint, which would be a very nice feature for CDNs, distributed networks and robust media servers.
Some other topics about TLS-IDs in SDP and FlexFEC were discussed but I had no idea what they were talking about.
tsvarea
The findings of a paper on non-volatile main memory (NVMM) by NEC Labs Europe were presented at the Transport Area Open Meeting.

NVMM is a far-along technology coming to mobile devices soon. Computers going back many decades have used volatile main memory, meaning the contents of RAM are lost when the power is turn off. There exists a major practical and abstract barrier between main memory (RAM) and persistent storage (SSD, disks) because of the differences in volatility, speed and capacity. With NVMM, main memory can be used as persistent storage. Of course it’s not quite that simple; NVMM costs are higher than RAM and much higher than mass storage devices, and not yet faster than typical DRAM. But it is an area with potential applications for accelerating certain tasks.
The researchers investigated the implications for networking, focusing on the use case of downloading a file over a network.
Right now when your computer is downloading a file the data follows a path from the Network Interface Card (NIC) to DRAM (using DMA I believe), then is read from DRAM by the OS networking stack, a read() by the application doing the downloading, then a write() to the storage stack, which is buffered into DRAM and then flushed to disk. This process was measured to have a latency of about 2000µs. By simply replacing the last bit with a copy from DRAM to NVMM, the latency was reduced to about 40µs, showing that the disk flush was extremely significant, as well as the cache misses involved due to the fact that the area of DRAM being read from was an ever-advancing pointer .
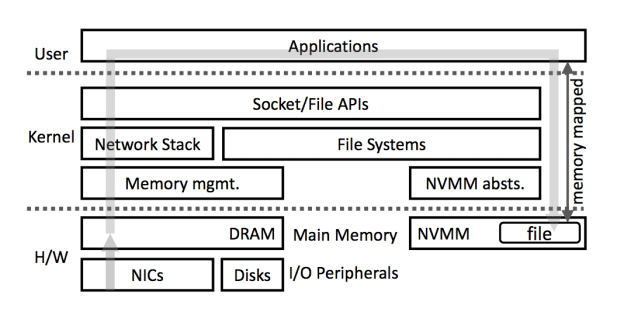
Part of their solution was to maintain a static ring buffer of packets and a small set of metadata entries containing offset/length indexing information of the packets in the buffer. This helped prevent cache misses as the region of memory for the packets remained fixed. The other change was to DMA packets to L3 cache instead of main memory, and only if packets needed to be stored was the cache flushed to DIMM. They said a 10-88% increase in throughput was obtained and a 9-46% reduction in latency, and the improvements scaled linearly with cores.
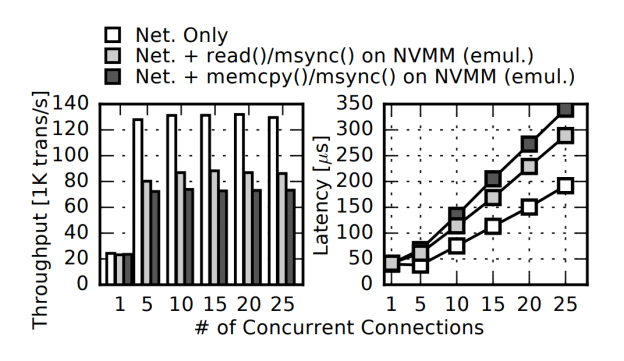
The researcher suggested that similar types of optimizations which change assumptions about the persistence of main memory storage can pay large dividends and that there are likely many such areas for taking advantage of NVMM capabilities. Exciting!
ideas
I attended a BoF session for IDentity-EnAbled networks.

From the very cursory glance I gave the Bof it superficially resembled a topic I’ve long been interested in: the concept of a universal mechanism for identity on the internet. I’ve long thought it would be a massive step forward of internet services could make a basic assumption about the requestor, such as every request containing a public key. Say every request made to a website contained such a public key; you wouldn’t need to register a separate username and password at every site you visit. You could have one universal identity or generate new ones on the fly as desired, it would strongly prove that the requestor is in possession of an unfalsifiable key but also provide pure anonymity at the same time. All data could be end-to-end encrypted and stored securely such that only the owner of that identity could read it, and so much more, all with a very simple change. I even wrote a ton of code for a project for a new application layer based on this concept about ten years ago but I got a little too carried away on the scope of it and there was no possible way I was going to do it by myself.

So I was excited that maybe there would be efforts towards standardizing this simple but powerful idea at the IETF. Part of the agenda was a system that even had the same name as my project! Imagine my disappointment when I learned that their plans were impenetrable soups of acronyms and incredibly complex and confusing academic-speak.
Much of the blame lies with me for not reading through the materials ahead of time, to be sure. The IETF meetings assume everyone is up to speed on all the drafts and documents and mailing list traffic. As a newcomer trying to sample many different projects I simply didn’t have hours and hours to read over all the drafts before going to the different meetings. However at all the other sessions I attended I mostly got the gist of everything even if I was not intimately familiar with every detail and issue of conflict at the WG. The IDEAS session was very different.
The session discussed the definition of an identity-identifier split, defining an identifier as something similar to but not quite an location identifier, which could be a “valid but often non-routable v4/v6 address” and could “be truncated but managed within a domain of use”. An identity belonged to a machine, not a person. A concept of HIT (host identity tag) for the HIP (host identity protocol?) was a ‘flat’ namespace of identity tags which were v6 address looking things. They wanted to separate identifiers from locations, as “IP addresses have overloaded semantics going back to 1993”.
While I should mention again I didn’t do the reading before class, I do have a considerable background in related topics and I didn’t understand the point of their discussion at all and everything seemed mind-bogglingly complex and there were dozens of acronyms tossed around that I’d never heard of. Their solution required complex service topologies with lots of arrows and diagrams, considerable infrastructure, and even a design for HIP that “requires changes in the IP stack.”

I feel how the co-chairs look right now
The ideas presented at IDEAS were so dense, complex and impenetrable that I simply can’t imagine any kind of widespread adoption of whatever it is they were pitching. As someone who designs and builds complex systems for software services I have a bad reaction to obviously over-engineered systems and generally prefer simpler and easier to understand, if less powerful solutions. The technical sophistication of a system must be balanced with actual human concerns about ease of adoption, ability to communicate the design in a clear and concise way to other humans, and make the benefits and trade-offs clear so other humans can make informed choices about your system. This was the only session I attended that felt utterly doomed and depressing and I couldn’t sit through the end. In fact it bothered me so much that I did something I was not supposed to: got up and asked a question without reading all of the materials ahead of time. I paid to be here, might as well get my money’s worth.
“I have a stupid question…” I said to the presenter.
Speaker: “There are no stupid –”
Me: “This all seems incredibly complicated and dense and difficult to grasp. Why not use a public key as an identifier?”
Speaker: “Which format of public key and what algorithm? (is this ID_KEY_ID??)” [language from official meeting notes]
Me: “OpenSSH key format.”
Speaker: CLEARLY you did NOT read the drafts and YEARS of hard ACADEMIC RESEARCH and [your question is stupid].

GRIDS PoC
cellar
The Codec Encoding for LossLess Archiving and Realtime transmission WG was full of great progress and news. Its charter is related in a fashion to the internet video codec WG in that both are standardizing free and open formats for multimedia in an effort to not get the entire world stuck in a trap of being burdened with de facto standards of proprietary and royalty-encumbered audio and video formats. cellar is focused on lossless archiving of multimedia, as in the United States’ Library of Congress as one example. If digital multimedia is to survive many years of technology changes and new formats it must be encoded in a well-defined standard and not lose any quality.
From the charter:
“The preservation of audiovisual materials faces challenges from technological obsolescence, analog media deterioration, and the use of proprietary formats that lack formal open standards. While obsolescence and material degradation are widely addressed, the standardization of open, transparent, self-descriptive, lossless formats remains an important mission to be undertaken by the open source community.”
In a nutshell (or Matroshka), the group is defining normative guidelines for an official format to be used for representing lossless audio and video data and containing them. The choice has been made of Matroshka (.MKV) for the container, FFV1 for video, and FLAC for audio. FFV1 is already specified for archival use by the US Library of Congress, and FLAC is widely used by audiophile pirates.
Issues discussed were problems with the existing specifications vs. the reference encoder, which has some known issues like integer overflows and incorrect colors, which are supported by the reference decoder. The next milestone and format version is removing these documented exceptions and “documenting reality” instead.
The illustrious open-source media codec library ffmpeg supports Matroshka binding V_FFV1 CodecIDs without a compatibility layer but doesn’t write out the codec ID by default in ffmpeg to preserve compatibility with older versions of ffmpeg. They are ready for the future with a native FFV1 codec ID.
The FFV1 coder description is described except for the description of the single-pixel Pixel() function. Much is already written in plain english but a normative C-like description should be given.
FFV1 v4 should support more pixel formats and add native metadata, not relying on the container (MKV) for metadata. FFV1 can transport its own metadata as well.
A description of Matroshka was given live via remote video feed (naturally) along with some historical context. It was started in 2012 to store live TV captures because existing containers were unsuitable for them. It was forked into its own project due to disagreements with the community. It borrowed ideas from AVI, Ogg, XML and semantic web ideas. Later on the codecs H264, H265, VP8, VP9, AC3, DTS, and Opus came. It was adopted by Google and Mozilla for their standardized “WebM” format, designed to be a standard for free and open multimedia format for the web, consisting of VP8 or VP9 for video and Vorbis or Opus for audio. It is used and supported today but not well-supported by Apple and Internet Explorer due to evilness and greed (see netvc above).
Matroshka/WebM is widely supported by open source software players, Windows 10, blueray, smart TVs, Netflix, Nintendo, Youtube. Recently 360° video and HDR metadata support was added.
Question: “What is the plan for documenting WebM? Will that be a part of the cellar specification?”
Speaker: “WebM is basically the Matroshka specification online, WebM doesn’t have anything not in Matroshka. Matroshka all applies to WebM and the spec says if it applies. They are the same format. I wish Google would help us work on this spec. Mozilla and Google people are on the mailing list but aren’t helping with the spec.”
The cellar working group’s IETF documents are generated from Markdown and EBML-defined XML files. XML semantics defining EBML can used to generate code, including all parts of WebM. The Matroshka v3 spec was submitted July 2017, and in September the v4 spec is due to be submitted. The specification is a huge task comprising 243 element, 33 of which are deprecated. There are seven pending pull requests, text clarifications and codec definitions, and 22 known issues remain, mostly text clarifications along with some format additions, formatting changes and codec definitions.
saag
The Security Area Advisory Group met to listen to some invited talks on security-related topics relevant to the work of the IETF.
A long and fascinating talk (slides; recommended reading) was given by Kenny Paterson about post-quantum cryptography. PQC is one of those concerns that (as far as is publicly known) is not an immediate problem but something people should be thinking about and planning for well before the time it actually becomes a crisis, if indeed quantum computing ever reaches a point where it can break most classical encryption schemes currently in use today. There’s even an obscure filmabout this scenario called The Traveling Salesman.
For context, the timeline of a weakness of the hash algorithm SHA-1 was given:

The point being that there were many years between the discovery of a theoretical weakness and an actual successful attack, with a standards organization (NIST) trying to promote an improved version, and resistance by the complacent commercial certificate authorities. That is until they had a change to replace their certificates with SHA-2 after mass revocations due to the OpenSSL “heartbleed” vulnerability.
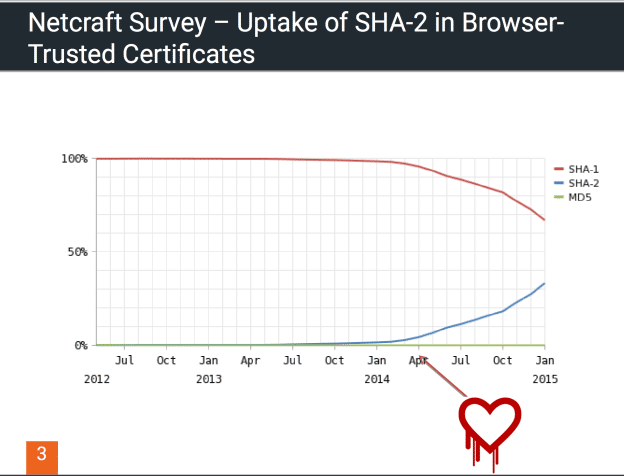
So a sane route might be to continue research today to potentially protect against future quantum computing attacks on classical cryptographic methods or at the very least explore and document interesting alternatives to prime factorization and elliptic curve crypto. Some of these include lattice-based, code-based, non-linear, and ECC-isogenies and I haven’t the foggiest notion what those are.
Is significant quantum computing on the horizon? People have been saying QC is “a decade away”, for several decades now. Also the quote “In terms of fundamental physics …. we’re pretty close to what we need. There’s just tonnes of engineering work…” was mentioned, to the laughter of the engineers in the audience. The speaker said quantum physics laws have been verified to around ten decimal places, which isn’t all that great. Some relevant questions are: “is quantum computing solid against advances in physics?” versus “is public-key crypto vulnerable to algorithmic advances in conventional algorithms for factoring, discrete logs, etc.”
There exists a company D-Wave which produces fantastically machines kept at near-zero temperatures for “quantum annealing” with some notable customers. Quantum annealing is a quantum version of simulated annealing, a common optimization technique in which the “energy” of a system decreases and settles on more local minima/maxima as time goes on.
There have been publicized advances in quantum-key distribution, such as a recent experiment using QKD over long distances by China with mainstream media headlines like “unhackable encryption” and “the future of security”. It should go without saying that such reports are dubious. For one, QKD isn’t really distribution – it expands existing keys. This can already be done with key derivation functions (e.g. PBKDF2) with classic cryptography. The problem with QKD is that it doesn’t work for any great length, there must be signal boosting components which decode and then re-encode the transmission stream to send it over long distances, preventing end-to-end encryption over distances. The UK’s NCSC (formerly GCHQ) took the unusual step of publishing a white-paper bagging on QKD and describing its infeasibility.
The IETF is developing two drafts for hash-based signatures which are considered mature. Other PKC schemes are being researched but not anywhere near standardization. The suggestion was made that IETF should not lead the standardization effort for PKC but instead follow the lead of the US NIST, and for the present the IETF should care not to bake in any algorithms yet, such as too-small maximum field sizes.
Ways Forward?
Participant: “current estimates for key sizes are going to be an order of magnitude larger… so like 50k-bit key sizes. If you have a protocol like UDP where everything fits in one packet, you’re going to have a bad time.”
Participant: “I do have a PhD in nuclear physics and I don’t think QKD is going to work because the engineering parameters are too hard. .. We need a deployment plan for this now, before we have any crypto.”
Another (brief) talk was given on the p≡p (pretty easy privacy) project, a software engineering effort to improve interoperability of privacy and cryptography between instant messaging and email applications, in the vein of S/MIME and OpenPGP. The speaker said that the IETF could help with MIME-based message formats, key synchronization, base protocol mapping for email, Jabber, URI schemes for missing message addressing such as GNUnet, signal and so on. They said they had a library available with adaptors for Java, C#, Python, Obj-C, Swift and more, with actual software written for Android, EnigmaMail, Outlook, iOS and Email/p≡p. It sounded like a great project and opportunity for IETF standardization and real engineering effort to come together in a standards-based effort to increase privacy, trust and interoperability all at the same time.
Conclusion:
All in all the meeting was a great way to not only learn about lots of intricacies and interesting technical problems that smart people were trying to solve, but to see the process of creating and implementing standards crucial to the openness and freedom of the internet. This work is something that so many people take for granted and they don’t appreciate the constant ongoing difficult effort that thousands of people do to prevent corporations or governments from monopolizing the function and operation of the internet.
The IETF is distinct from other standards bodies such as the government-influenced ITU or the vendor/carrier-driven 3GPP group for wireless network standards. Without work being done in the open and distributed through a community of volunteers, nefarious actors can and do try to dictate their proprietary solutions for technology, often for their own financial benefit and not necessarily in the interest of the greater good.
Nobody forces the IETF standards on anyone; they are implemented voluntarily by engineers working on internet-related technology to promote interoperability and ensure the underlying protocols, transports, networks and formats remain free and open. Everyone chooses to implement the IETF standards because of Metcalf’s Law: the value of a telecommunications network is proportional to the square of the number of connected users of the system.
Recognition and support should be given to the work the IETF does to promote freedom and privacy around the world, and I encourage anyone to get involved and join the mailing lists and discussions of any working groups related to their interests.

Post-meeting feeding frenzy
About the IETF
The Internet Engineering Task Force (IETF) is a large open international community of network designers, operators, vendors, and researchers concerned with the evolution of the Internet architecture and the smooth operation of the Internet. It is open to any interested individual. The IETF Mission Statement is documented in RFC 3935.
The actual technical work of the IETF is done in its working groups, which are organized by topic into several areas (e.g., routing, transport, security, etc.). Much of the work is handled via mailing lists. The IETF holds meetings three times per year.
The Internet Society offers an IETF Fellowship Program to support technologists, engineers and researchers from emerging and developing economies. Applications for the IETF 98 Meeting in Chicago are now being accepted.